



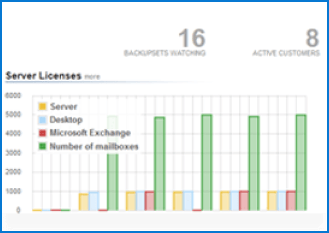
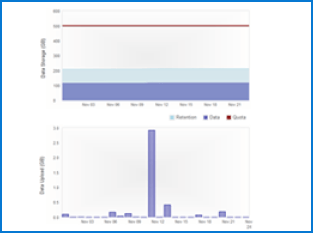

(£250 credit)
If you are moving from a competitive solution to BOBcloud, we can ease your transition with a £250 storage credit

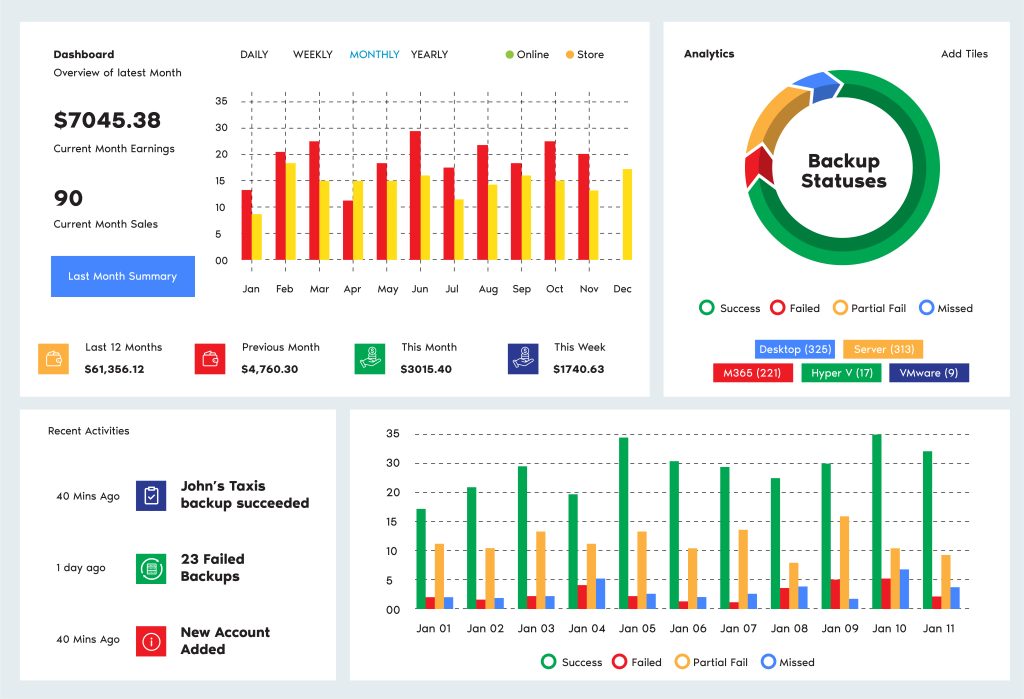
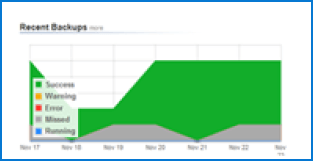
100% Reliability
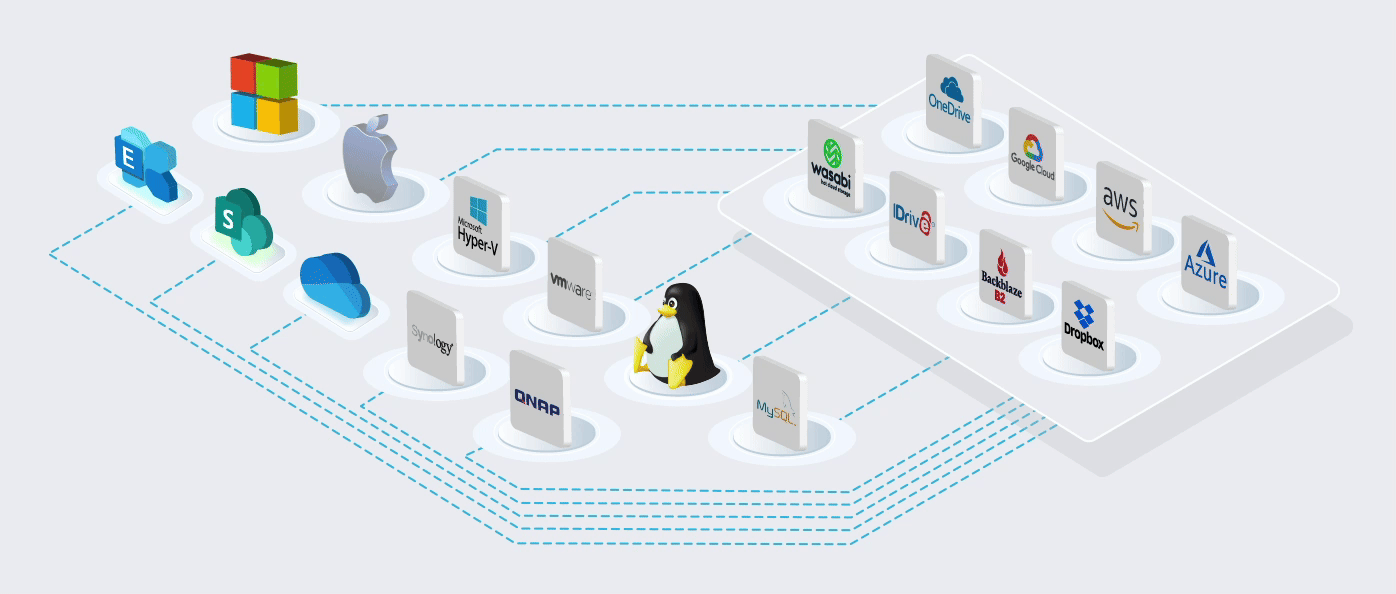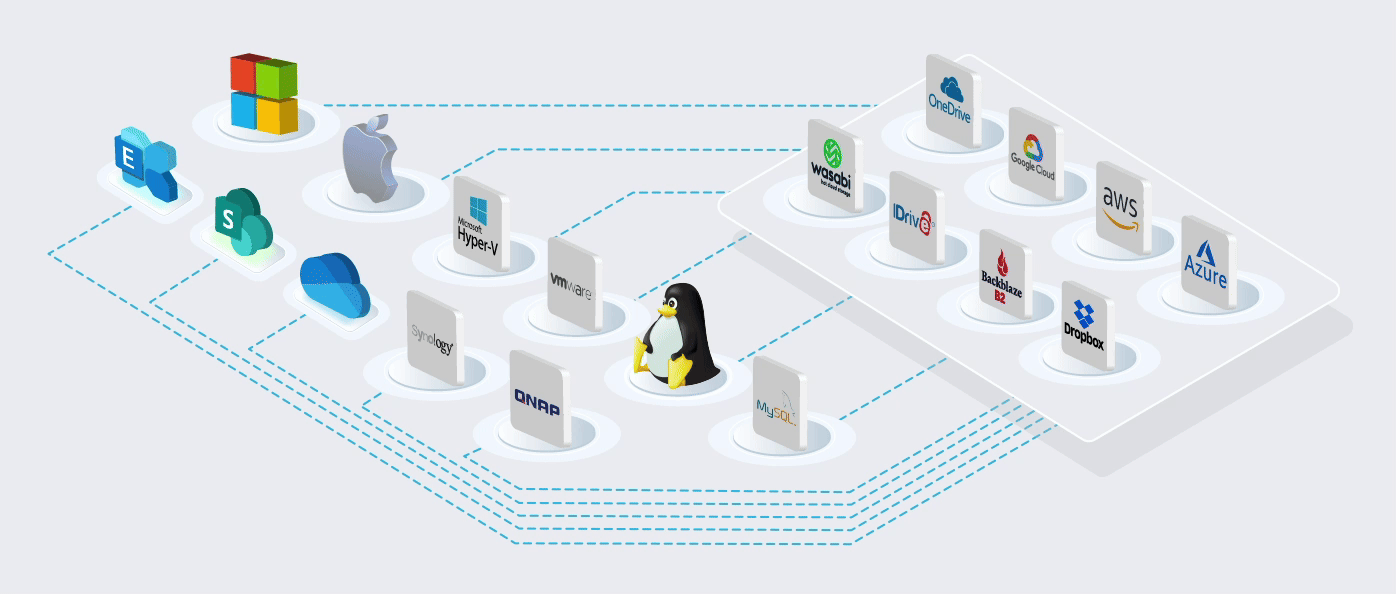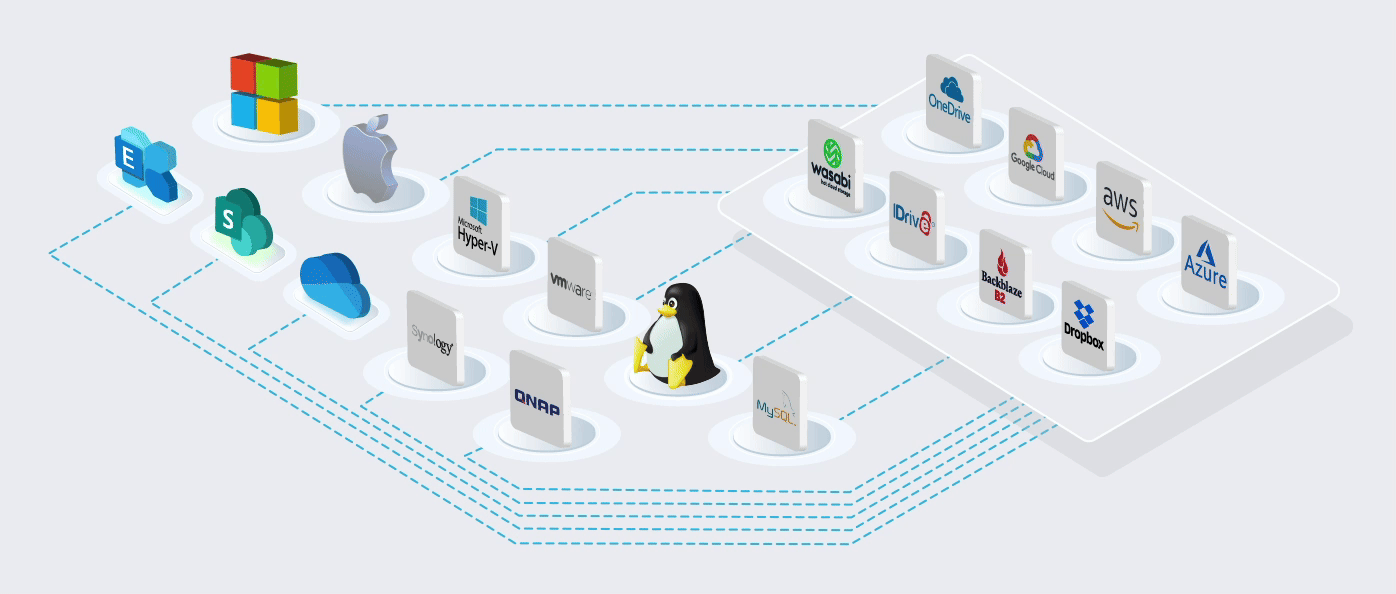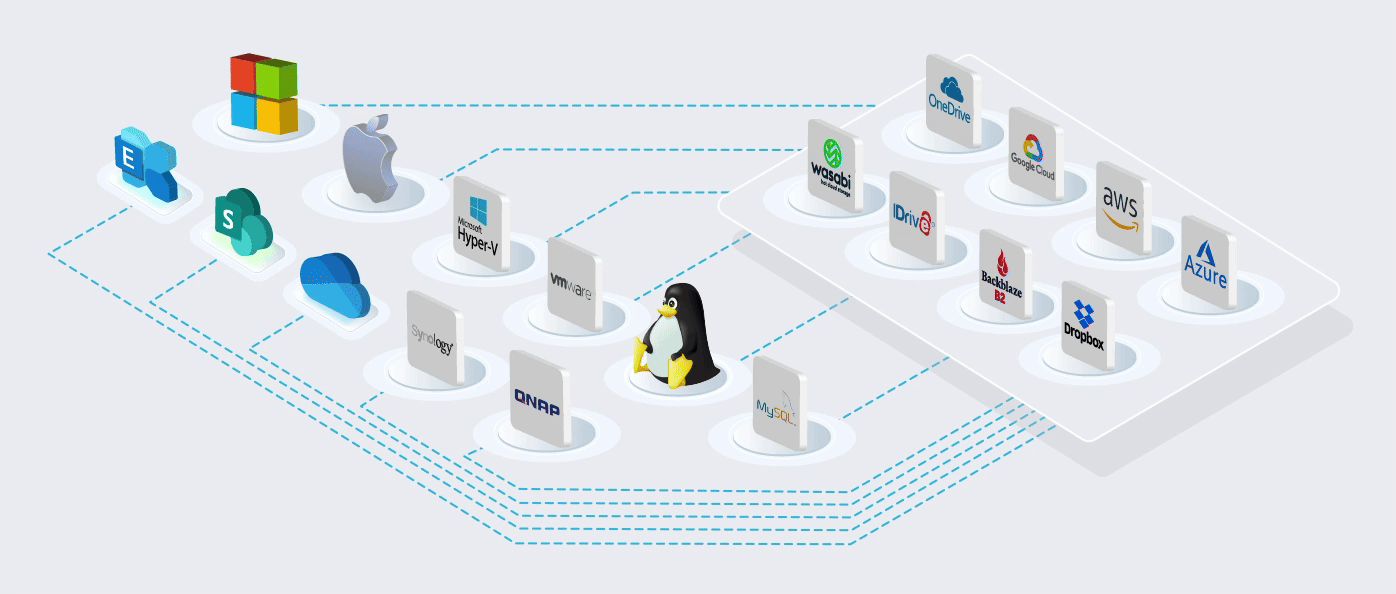
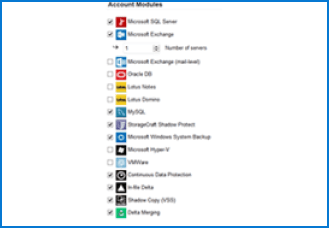
Store unlimited revisions of your data to multiple online and local locations. You choose your level of durability

7 Day Support
Our team are always on hand to provide quick 7-day-a-week support. We have a knowledge base and a community forum
