Data Protection Services
Since 1999
Automatic 24×7 cloud backup and storage for MSPs and Resellers.
ISO 27001 and SOC 2 Certified Storage.
All our cloud storage destinations have a guarantee of 11 Nines of Data Durability. Read more
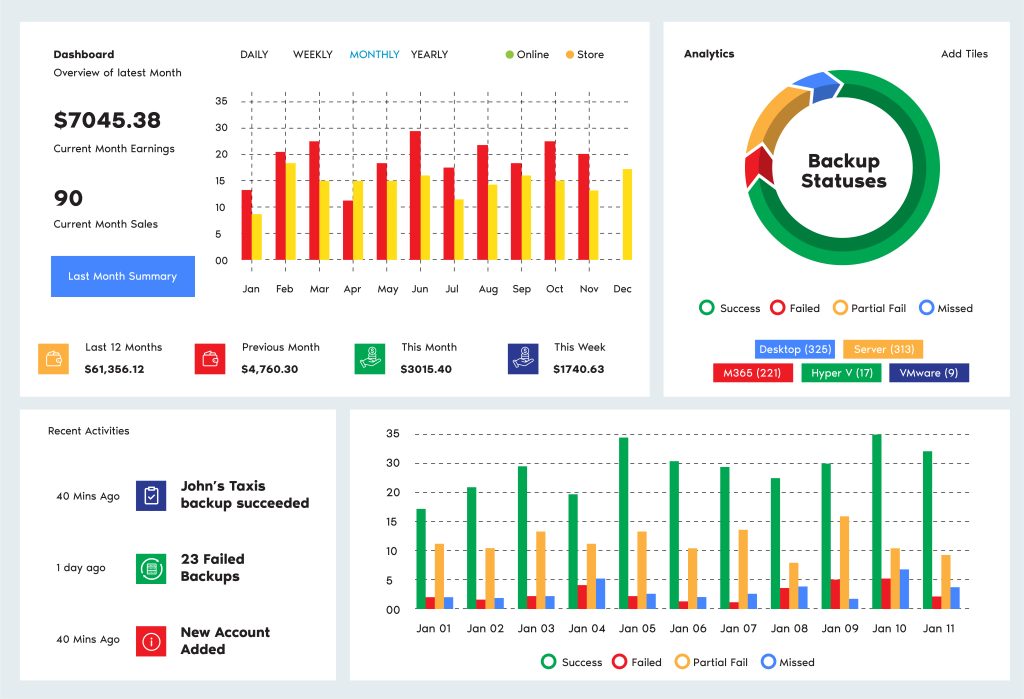
Backup Anything to Anywhere
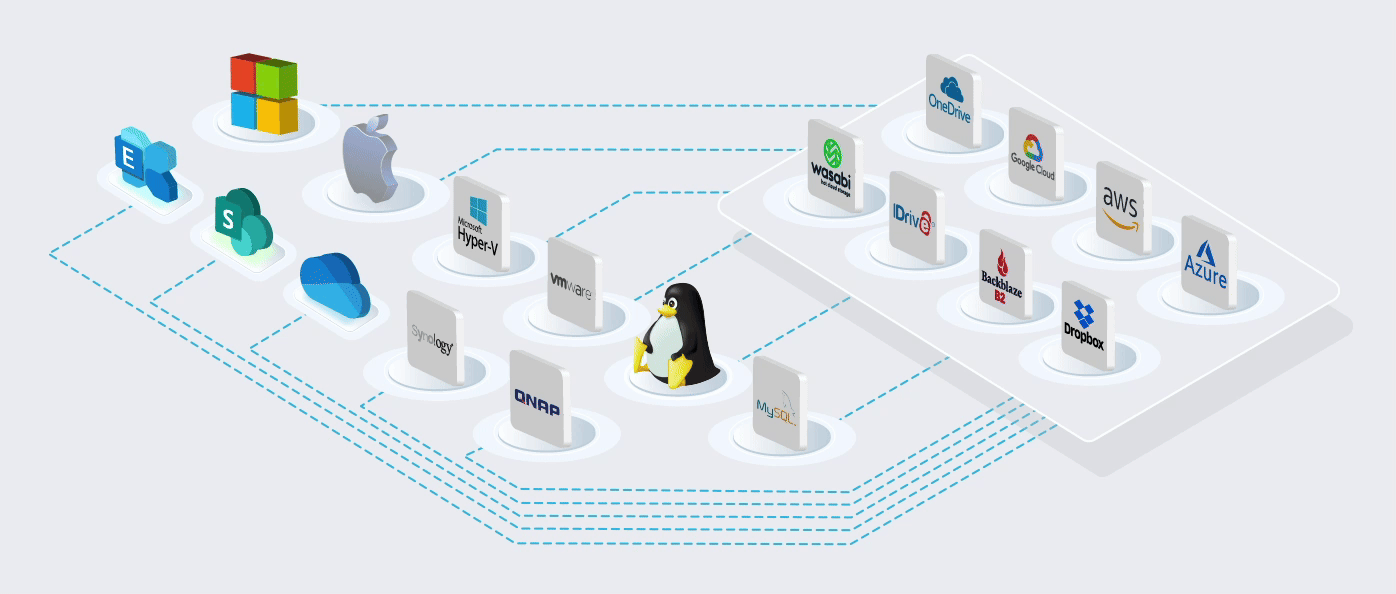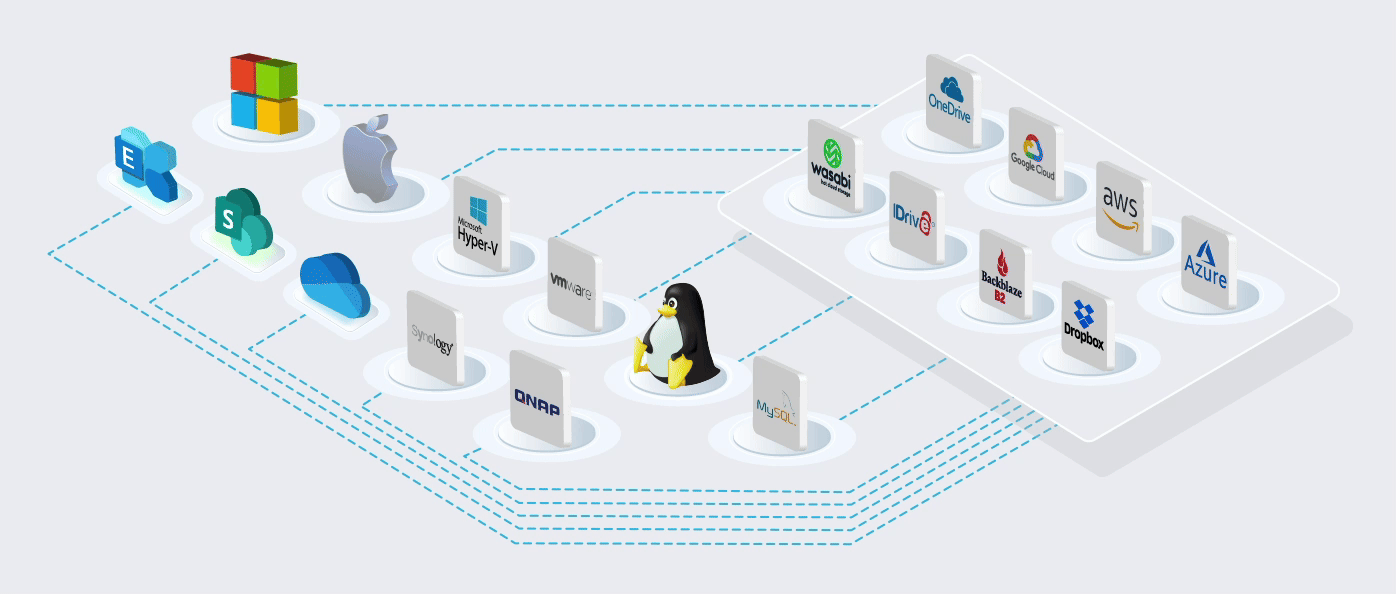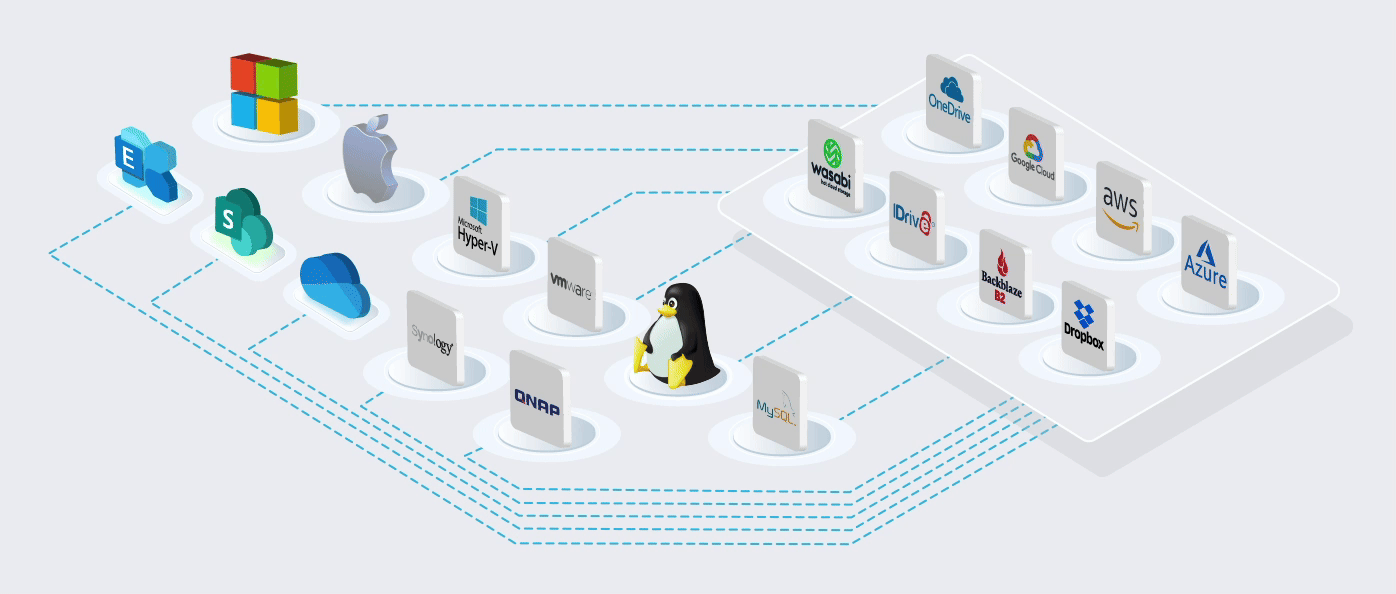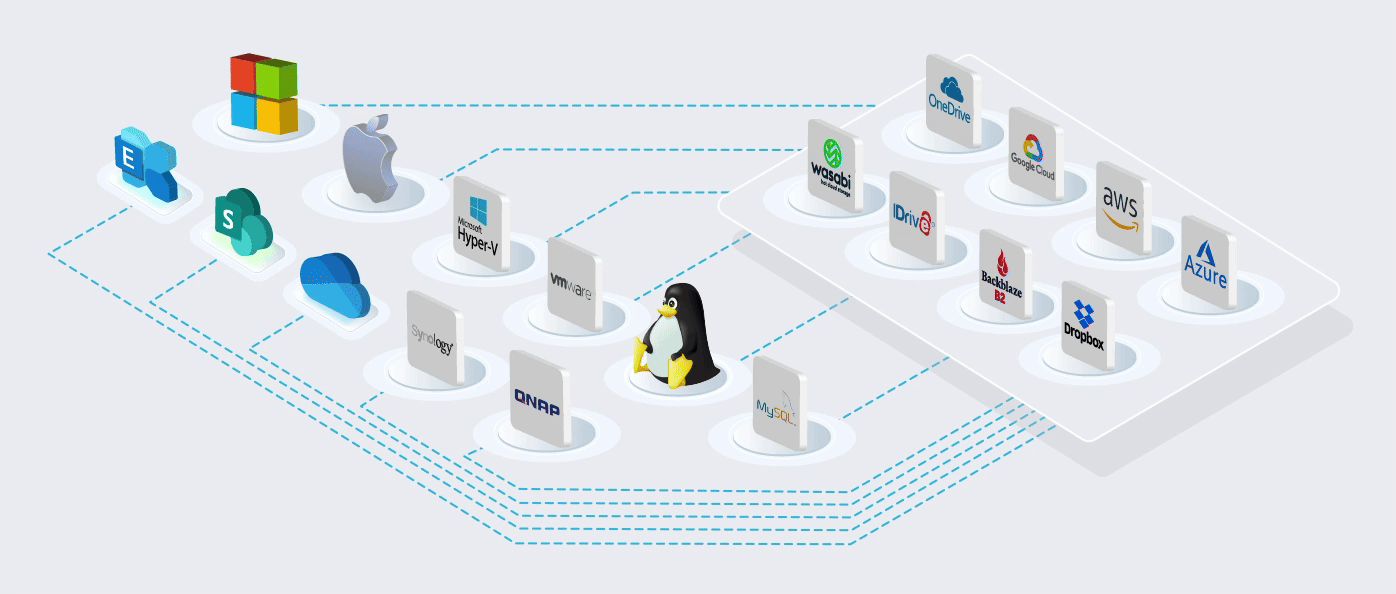
Built on the World's most Trusted Cloud

Using Microsoft's cloud [Azure] in more than 60 regions worldwide. ISO/IEC 27001:2013 storage
The Microsoft cloud is trusted by Governments, Police, Military, Medical, and Corporates worldwide. It is the most trusted cloud in the World and has the most compliant and certificated data centres worldwide.
WHAT IS CLOUD BACKUP
Cloud backup, also known as online backup, transfers a copy of a database or physical or virtual file to another physical location for disaster recovery.
CLOUD STORAGE
Cloud storage provides functions similar to backup and allows you to remove data from your local devices and share your files with anyone else.
MICROSOFT 365 BACKUP
BOBcloud’s cloud-2-cloud Microsoft 365 backup removes the risk of losing data. Your data is backed up and restored to the M365 cloud.
PREVENT RANSOMWARE
Restoring your data is the only proven way to recover from ransomware. To do that, you must have a solid backup strategy.
Why You Must Backup Microsoft 365
Protect every M365 entity in Exchange, SharePoint, OneDrive and Teams with unlimited history retention.
Protect your customers from unknown security threats, Ransomware, Accidental Data Deletion, and more.
Simple click-to-restore feature to recover any data from your backup to the Microsoft Cloud.

Data Protection Solutions
Data security must be applied to every stage in the lifecycle of your data. We encrypt your data chain end-to-end during backup, transfer, rest and restore.
Even if someone were to capture your data packets during transfer, they couldn’t decrypt the data in your cloud storage.
GDPR is always paramount in our methodologies, so we never routinely capture personal data.
We might capture it when you create an email alert or an account name on our system. Where we do this, we will only use your data to send you status alerts on your backup sets and data.

One portal for everything
Cloud Storage Automation
Manage all accounts from one screen on your hosted Reseller portal. Add extra staff and assign their permissions using role-based administration. There is no requirement to purchase additional software or hardware or increase staffing costs.
Enjoy unlimited and automated online cloud storage backups and restores with convenient around-the-clock accessibility to your backed-up data.
Your trials will be unlimited for 30 days. Email and remote support are provided seven days a week.
You can monitor the usage of your destinations quickly and set alerts from your portal.
No one is on contract, and you can terminate at any time.


(£250 credit)
If you are moving from a competitive solution to BOBcloud, we can ease your transition with a £250 storage credit

100% Reliability
Store unlimited revisions of your data to multiple online and local locations. You choose your level of durability

7 Day Support
Our team are always on hand to provide quick 7-day-a-week support. We have a knowledge base and a community forum
What is UK Cloud Storage?
Ease of access and availability: Cloud storage allows you to store your backups online, restoring your data anytime from anywhere.
Fast scalability: Cloud storage makes it easy to scale your resources up or down as needed without investing in additional infrastructure. This is especially helpful when you experience an unexpected increase in data volume, as it allows you to maintain business continuity.
Data redundancy: Storing the same data in multiple places is essential for an effective, durable backup. Storing your backups in the cloud ensures your data is safely stored in a remote location, protecting it from natural disasters, accidents, and cyberattacks on your main site and data source.
Cloud storage will save you the hassle and the cost of hardware, data center storage, power, cooling, and techie costs to maintain your backup storage.
How BOBcloud Protects Your Critical Data
We have been providing rebranded Business and Enterprise cloud storage backup services to resellers, MSPs, and IT Support Consultants in more than 20 countries since 1999.
Our systems are accredited ISO/IEC 27001:2013, and all our storage is certified to provide 11 Nines of
data durability.
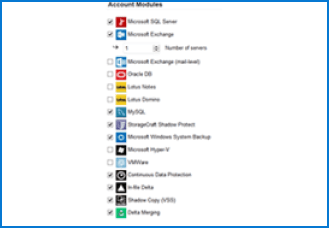
Protect all your customers’ OS and applications on their LAN and cloud. Our software and modules come pre-configured with 1,000+ cloud connectors, so you can store your data wherever you
like either locally or in the cloud.
Our service is exclusively provided to MSPs requiring an IT Reseller Backup product. If you need a backup for three devices or less, we will put you in contact with one of our resellers in your region.
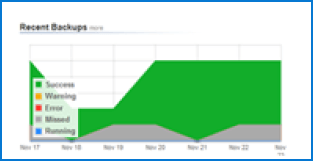
All our cloud backup modules are configured to run an initial full backup, then follow-on incremental daily backups. These settings can be easily modified to suit your business continuity requirements.
Test Data Restores are a Must
Backing up your systems with our cloud storage service is easy. However, that is the easy part. We know you must be able to restore your data correctly and quickly when needed. There needs to be more than a backup strategy; you also need a restore or DR plan.
If you have never restored the type of backup you are running, we advise regular test restores so that you can restore to your environment within your desired time frame and become familiar with the process.
Our experts perform daily test restores for our managed customers and can advise on ‘best practices’.

What is UK Cloud Storage, and how has it evolved?
In 1999, we started providing online backups to protect file servers running Exchange, SQL, and virtual environments.
In 2023, most of the backups our partners create are cloud-2-cloud and protect online cloud systems such as M365 (Microsoft 365), Azure, AWS, Google Cloud servers, and hundreds of other cloud-based applications and data systems worldwide.
Our software will allow you to back up your LAN and Cloud data to anywhere you like and restore it seamlessly.
- Windows Desktop
- Windows Server
- Windows server cloud backup
- Windows server backup bare metal recovery
- Windows server backup service
- Microsoft Exchange
- Microsoft SQL
- Hyper V
- MySQL
- VMware
- Mac OS
- Ubuntu
- OS’ and databases supported
- Synology devices supported
- QNAP devices supported