A failover system is a critical component of IT infrastructure that safeguards against system failures and data loss. By providing redundancy and automated recovery processes, failover mechanisms help organisations maintain business continuity and minimise downtime.
Table of Contents
In this article you will learn:
The significance of failover systems in ensuring business continuity.
The different types of failover configurations and how they function.
Best practices for testing, documenting, and maintaining failover systems.
What is a Failover?
A failover is a mechanism for shifting the operations of a primary server to another server. For instance, if the primary server experiences a hardware malfunction or permanent damage due to an unforeseen event, a robust business would want to shift its operations to another server.
Depending on the requirements and volume of the data, a single server or multiple servers could be used to shift the applications or operations to another server.
A failover system is more than keeping a secondary server on standby for emergencies. A robust failover strategy can include databases, RAMs, or any hardware or network-related component.
There can be a manual failover that requires human intervention or an automatic failover, where the process occurs automatically.
Importance of Failover Mechanisms in Modern IT Infrastructures
A suitable failover mechanism is something that every evolving business would need. The following are some reasons.
01 Business Continuity
Minimum downtime is crucial if the client base is significant, as even a 10% loss can significantly impact the company’s portfolio, particularly as companies grow through client satisfaction and maintain maximum high availability.
02 Reliability
Companies that rely on continuous online applications and real-time data must employ a failover strategy to establish a resilient network structure.
03 Data Loss
Data loss will occur if any primary network-related hardware or database malfunctions until the operations run smoothly again. However, a well-planned failover can help prevent data loss.
04 Reduce Financial Risks
When services are unavailable and clients cannot reach the business, significant financial and revenue losses can occur, especially for e-commerce and online businesses. Such an event will allow competitors to grab your valuable prospects and existing customers.
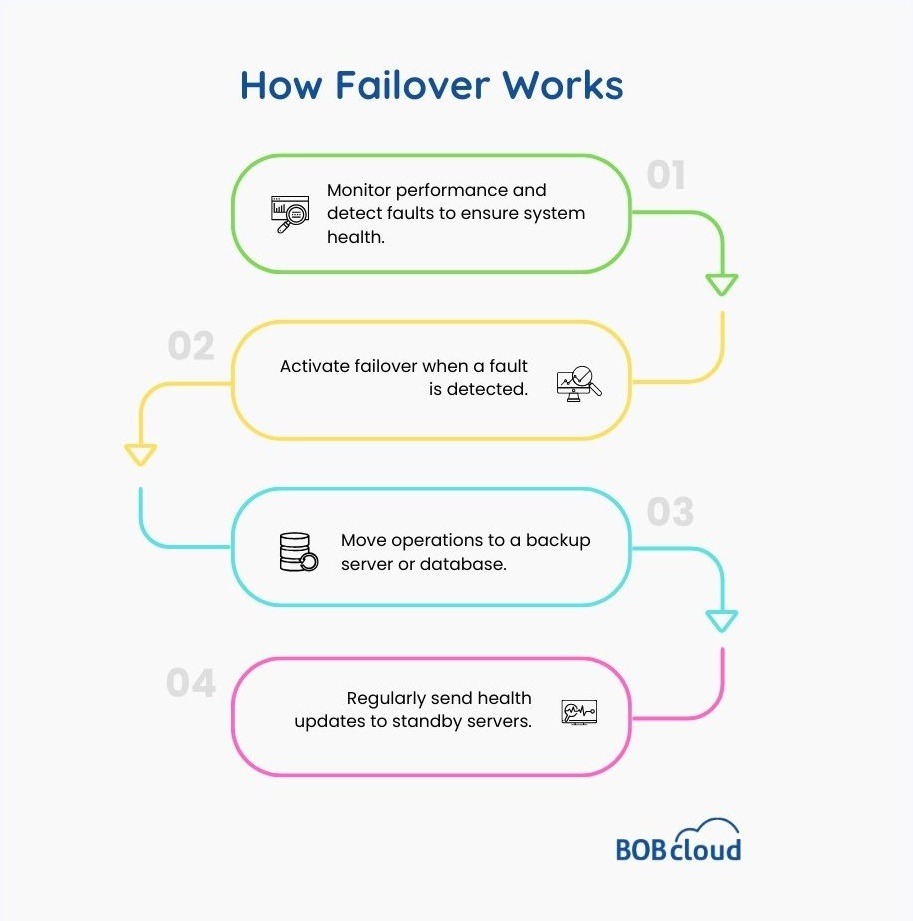
How Failover Works?
Understanding the mechanics of failover is essential for effective implementation. A well-designed failover system comprises several key components that work together to ensure a seamless transition during a primary system failure.
The following are some significant components of failover solutions.
01 Monitoring Systems
Some applications must monitor performance and other parameters to detect a fault. Such systems monitor health, identify signs of potential future issues, detect network problems, and detect possible software crashes.
02 Triggering Systems
After detecting a fault, a triggering mechanism must initiate a failover. As faults can occur with databases, hardware components, DHCP, DNS, SQL Server, or any other related component, each category must have a specific trigger. The system will determine which failover process to initiate based on a particular trigger.
03 Switching Mechanism
Triggers will inform you that something is wrong with your hardware or software. Once you have this knowledge, you need a switching mechanism to transition your current operations to another server or database. Some switching mechanisms also require administrative intervention to allow the switchover.
04 Heartbeat
A heartbeat mechanism should be a must-have component in your server failover strategy. In heartbeat mechanisms, the primary server connects with other standby servers and periodically sends them information about its health.
Suppose the standby servers detect that the primary server’s health is not satisfactory or is no longer receiving heartbeats. In that case, they will initiate a server failover, or an alarm will be triggered if human intervention is necessary for the failover.
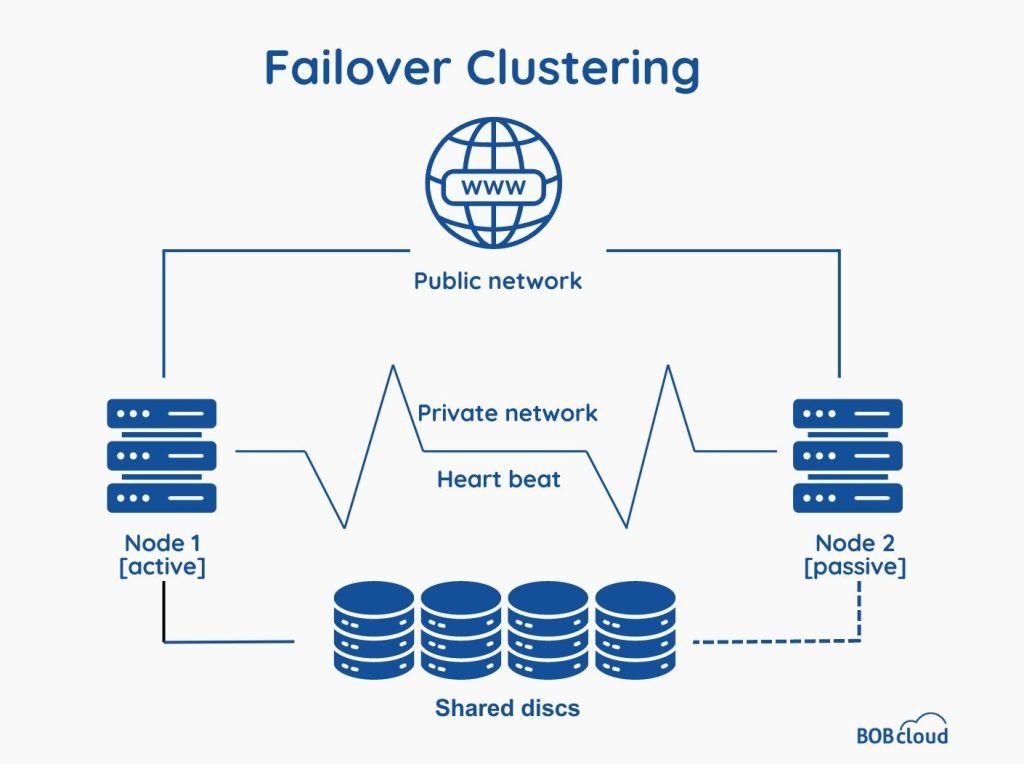
What Is a Failover Cluster?
As the name suggests, a failover cluster is a set of servers that work together to handle a data centre’s processes. If one server fails due to a fault, another server will take over the workload and keep the operation running.
In networking, each server in a cluster is referred to as a node. Every node runs its operating systems and instances. When failover initiates, other nodes handle the failed server’s workload, ensuring maximum uptime and continuous operation.
Each node communicates with others via a dedicated network whose responsibility is to check each node’s health and performance parameters. Synchronisation between the nodes is crucial for a quick failover. If any node experiences an issue, the monitoring system generates a trigger.
Failover Configuration Types
The architecture of a failover system can significantly impact its performance, cost, and complexity. Two primary configuration types are commonly employed: active-active and active-standby.
Understanding the characteristics and trade-offs of each is crucial for selecting the optimal approach for your specific needs.
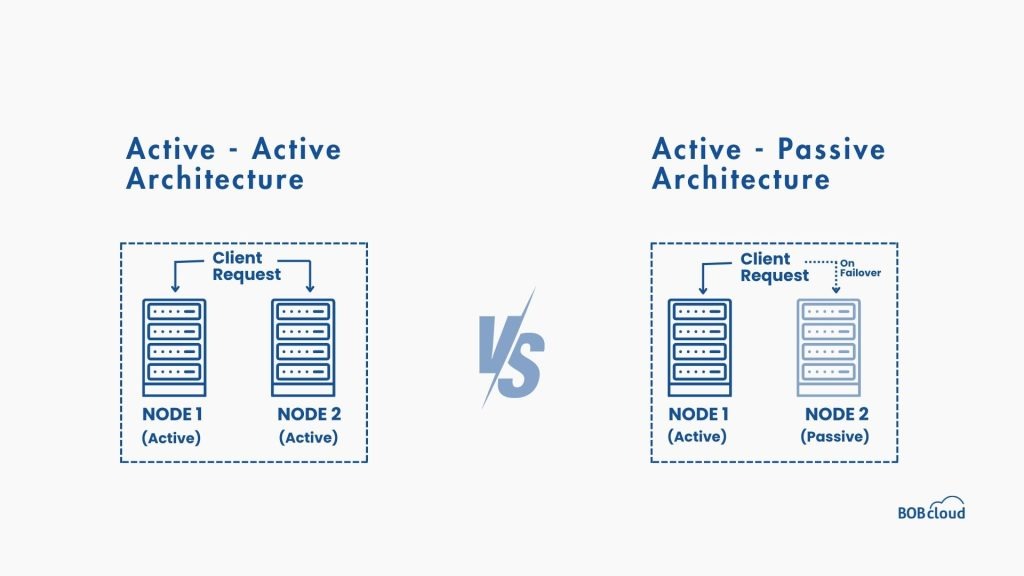
01 Active - active
In an active-active configuration, there are at least two active nodes. They run the same software, database, and applications to manage the data. If one node malfunctions, the workload is divided or distributed evenly among the other nodes.
An active-active configuration maintains an equal distribution of workloads to improve the overall response and throughput because no node is under overloading. The load-balancing algorithm will be according to the business’s needs.
An active-active configuration seems more like a load balancer failover. It looks different from a traditional failover mechanism but resembles a failover in some aspects. Both traditional failover and active-active configurations have the following elements.
Resilience
Redundancy of databases, servers, and hardware components
Continuous operation
Failover mechanisms, either manual or automatic
02 Active - Passive
Also known as an active-passive configuration, this configuration has at least two nodes. However, now only one will be active and running all the software and databases. The other nodes will be in a standby position and will only be operational if the primary node is down.
Since the passive node will replace the active node, all nodes must have the same settings and services. The same settings will ensure that customers continue to enjoy the same services even when one of your primary nodes malfunctions.
When an active-active configuration is in use, the outage time caused by a failover is virtually zero, as it only distributes the workloads across already running servers. However, in an active-standby configuration, the outage time caused by a failover can vary, as shifting operations to another server takes time.
Best Approaches for Failover
Implementing a failover system is only the first step. To ensure its effectiveness, organisations must adopt robust strategies for testing, documentation, and ongoing maintenance. The following best practices can help maximise the benefits of your failover solution.
Periodic Testing Drills
The primary question you must answer is whether the failover system will work. Does the system have the capability to transfer services to another server or database seamlessly? To answer the question, you would need to perform a deliberate failover.
Regular testing drills are essential for monitoring whether your failover plan remains effective. You can induce errors like detaching hardware components, shutting down databases, shutting down primary servers, removing primary DNS servers, and much more. See if the system successfully shifts to the redundant component.
Document the Process and SOP
Administration and employees can come and go as needed. They do not stay with the same company. If there is no documentation available and employees leave without providing proper training to others, problems may arise in case of emergencies.
To combat these problems, ensure that a document is created describing how the failover system works, what the triggers mean, how the monitoring system operates, and how to switch services to the standby hardware.
Conclusion
Failovers are an essential part of an optimised data centre. They ensure business continuity, increase reliability, reduce financial losses, and minimise data loss.
Besides these benefits, the article also explains how a failover system works and identifies its significant aspects or components.
A sound failover plan is essential for online and evolving businesses to maintain their services’ accessibility to customers for as long as possible.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.OKRead more